
Howdy nerds! We were exhilarated to receive a review unit of the cutting-edge Jetson Orin Nano developer kit from the NVIDIA Santa Clara team. Announced in GTC 2023, the long-awaited Jetson Nano successor is finally out in the market. Interestingly, the Nano successor is claimed to be almost 80x more powerful than its predecessor. It’s time for us to embark on a quest to stress this tiny monster out to its maximum potential! We do believe it has the necessary perks to be one of the Edge AI game-changers in the market.
In this blog, we shall make our first attempt to explore this embedded compute device and also assist newbies in becoming familiar with the basics of Edge AI.
What is Edge AI?
The era of computing has evolved to the stage where we don’t always need to rely on high-performant data centers for compute intensive tasks. Some part of the compute can be offloaded to mobile/portable devices on the network. Hence, this reduces latency and enables real-time industrial use-cases to be put effectively into production.
These mobile devices are nothing but edge compute units in the network. Hence, from an AI context, given there is a trained vision model available in the cloud data center, we can deploy it to a powerful edge device for inference. Mark the words – ‘inference’ and ‘not training’. The offloading of AI inference compute from cloud to instead edge part of the network can be termed as Edge AI.
A Typical Edge AI Pipeline
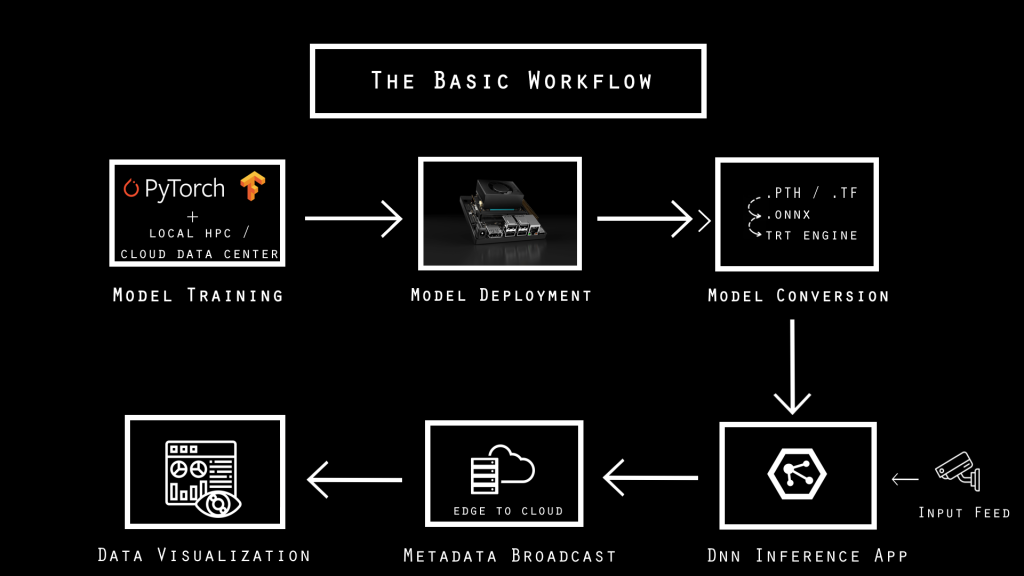
The above diagram elucidates a typical Edge AI pipeline in a simplistic fashion. We won’t be diving deep into each component in this blog but shall be exploring more on the same in the future. It all starts with model training which can be performed on a GPU-accelerated HPC data-center or an on-premise GPU based workstation. The next step includes model deployment to the edge device which we can term as (Cloud-to-Edge) component.
Followed by model-deployment, the next step involves converting the model into the edge-device native engine format. This is necessary to ensure high-performance parallel computing happens for inference. In the case of Jetson, it is basically a Tensor-RT engine. Tensor-RT is an NVIDIA proprietary DNN model engine framework for GPU accelerated computing.
The subsequent step in the pipeline is basically model-inference, which involves prediction with deployed models (say computer-vison based). A typical model-inference application’s role is to take input frames/images from source (live/offline footage), pre-process each image and identify objects of interest in a particular frame.
Next, it’s all about what we do with the inference data obtained. We could use it to perform event-triggering or just broadcast it to the cloud for business insights.
The Jetson Platform
The highly capable NVIDIA Jetson platform is tailored for Edge AI and Robotics applications. It comprises a series of powerful embedded systems that are capable of running complex deep learning models in real-time. The Jetson devices come with an onboard GPU and CPU and are designed to handle compute intensive tasks, making them perfect for a variety of applications such as robotics, drones, and autonomous vehicles.
The Jetson family started with the Jetson TX1 kit back in 2015. Over the years, the NVIDIA edge ecosystem has evolved to a stage where the tiny, embedded supercomputers come pre-packaged with matured industry ready software images fine-tuned for industrial use. The image below depicts the landscape of Jetson software.
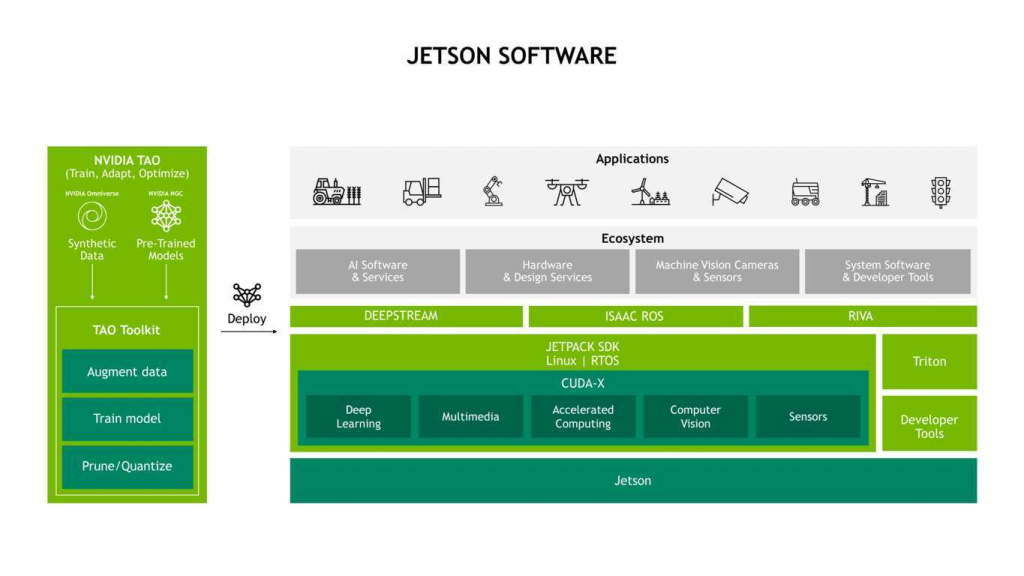
The Jetson Nano, introduced in 2019, created a storm in the industry for its lower price-tag. It allowed a larger community of researchers and developers to access the most affordable AI supercomputer available. Fast forward to 2023, and we have its successor, the Jetson Orin Nano which is a giant leap over its predecessor.

The Jetson devices primarily feature the Tegra chipset embedded SoC, which has been predominantly used in hand-held gaming consoles and semi-autonomous vehicles.
Nano Goes Orin Mode
Since the older Jetson Nano came out in 2019, a lot has definitely changed in the Jetson ecosystem. In the following sub-sections, we share a brief overview of the brand-new Jetson Orin Nano unboxing and first boot insights.
Boxed Treasure
The product packaging of Jetson Orin Nano is very premium and eye-candy! Upon sliding the black-cover, one will notice two individual compartments. The cables and the manual are on the left side, while the dev-kit is on the right.
Unlike the prior Jetson Nano, its successor comes pre-packaged with a power-adapter and cable to plug into its DC barrel jack.

Neo Specs

The older Jetson Nano based on Maxwell architecture featured 128 CUDA cores and came with 4GB and 2GB variants. While its sequel, Jetson Orin Nano is based on the market latest Ampere architecture, and has two memory variants: 4 GB & 8 GB. These variants feature 512 and 1024 CUDA cores with an additional 16 and 32 Tensor cores respectively.

The preceding model is equipped with a quad-core ARM Cortex A57 processor running at 1.43 GHz, whereas its successor boasts a more advanced hexa-core ARM Cortex A78AE processor (@1.5 GHz). However, unlike its predecessor, the Jetson Orin Nano doesn’t have any hardware encoders. We raised this as a query to NVIDIA, to which they responded about the software-encoding with reserved 1-2 ARM cores as sufficient enough. It will be very interesting to benchmark and analyse some performance numbers on the same.
The I/O panel in the Orin Nano dev kit has quite a few changes in contrast to its predecessor. It features 4 USB 3.0 ports with an additional USB-C port that acts as a power input (7W mode) to run the device. It doesn’t come equipped with an HDMI port anymore and rather has a display-port (DP) to be the sole means to connect the device to an external display. Of course, you can connect a DP-to-HDMI adaptor to the DP Port.
The DC barrel jack enables you to operate the device at 15 W. To connect with other embedded units like Arduino, sensors, etc. you can use the 40-Pin Expansion Header (UART, SPI, I2S, I2C, GPIO). For cooling, the device is equipped with a fan connected to the 4-pin header. This fan is encased with a heatsink which gives the whole dev-kit a neo-noir look.
Bootup, Power GUI & Analytics

The device can be powered on by connecting it to one of the DC inputs (DC Barrel Jack/USB-C). For first boot, the necessary pre-requisite is flashing a UHS microSD card with the latest JetPack image using Balena Etcher. The latest version of JetPack is based on Ubuntu 20.04.6 LTS (64 bit). One can also flash an M.2 SSD to get better performance in booting and data loading/transfer.
Post completion of first-boot formalities and login, one can witness the simple yet elegant Ubuntu desktop screen running on a Tegra chip. Tegrastats take a different turn this time with pre-packaged power GUI utilities. One can head to the power menu located on top right corner of the screen and click on Power GUI to view the device metrics (see below image).
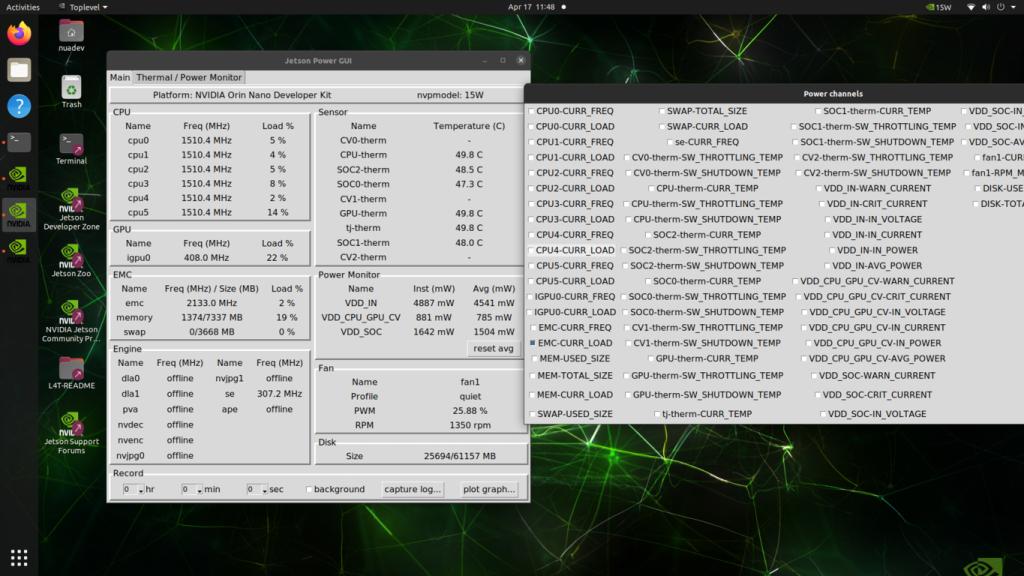
The Power GUI tool also features a graphical visualization utility to plot time-series graphs for device metrics.
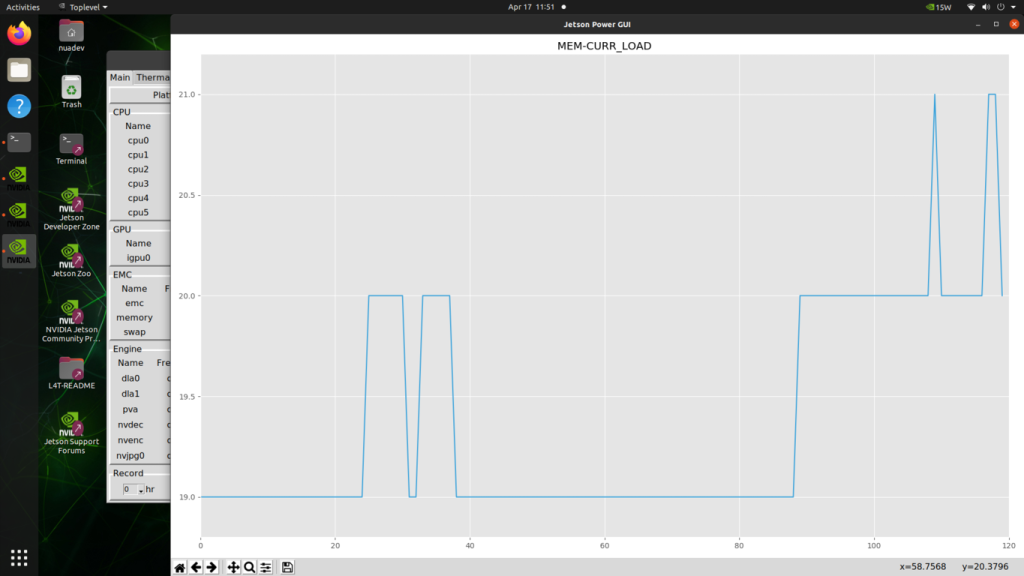
Jetson Orin Nano Benchmarks
The judgement time is finally here to assess the Jetson Orin Nano! Let’s see the prowess of this beast as we embark on an interesting adventure with it. Most interestingly, without the inclusion of hardware-encoders how does the Orin Nano fare in rendering AI inference output videos? Let’s dabble deep into it!
Crowd Analytics
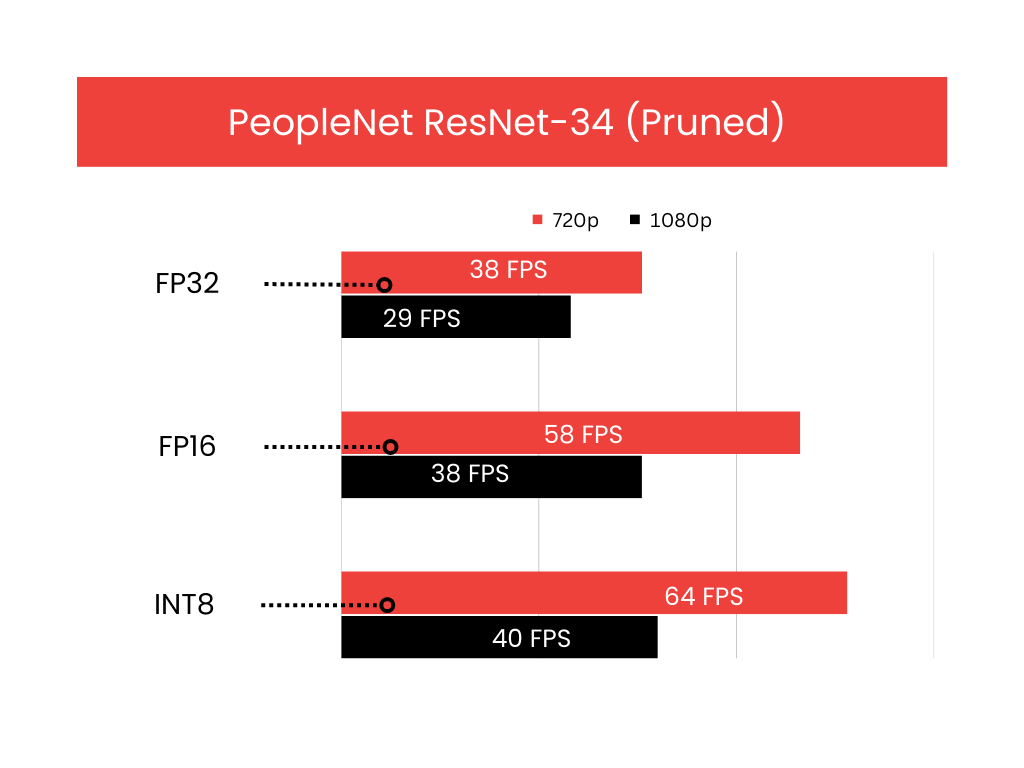
We leveraged the NVIDIA DeepStream SDK to get some quick numbers on AI inference with Jetson Orin Nano. DeepStream is an Intelligent Video Analytics (IVA) Toolkit from Nvidia with which you can primarily build vison AI applications with ease for production use-cases. Recently, support has been added for its integration with Conversational AI applications as well.
The initial use-case we targeted was Crowd Analytics (people identification) in a bustling metro-street. The PeopleNet model was utilized for this which is available in the NGC catalogue as a pre-trained model card. This object-detection model basically identifies people and faces on an input frame/image. It accepts around 960x554X3 frame size in its input layer which is enough to highlight how compute intensive the inference is going to be! The model by default happens to be in .etlt format which needs to be converted via TAO Converter to transform it into a deployable TensorRT engine for the Jetson Orin Nano.
The graph mentioned earlier depicts the performance crunch we witnessed across all supported model-precisions (FP32, FP16, INT8). The key-performance-indicator (KPI) metric here is inference output footage in frames per second (FPS) in 1080p and 720p resolutions. The input footage we provided was a 1080p video.
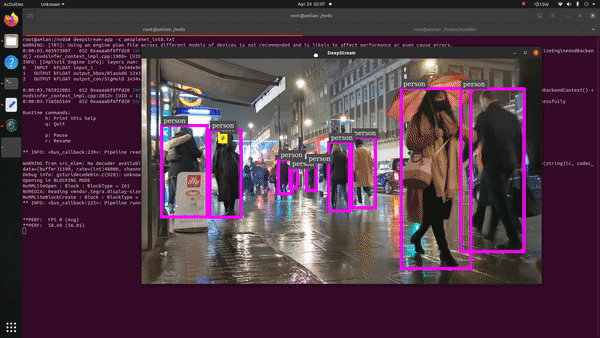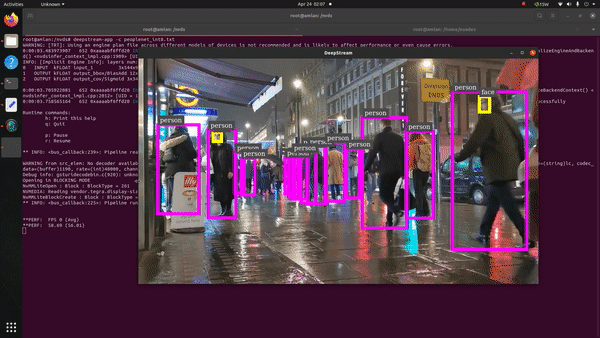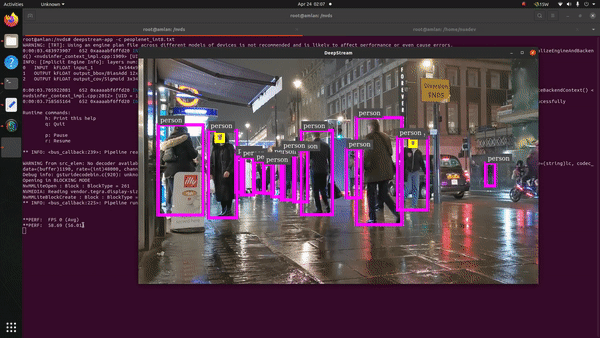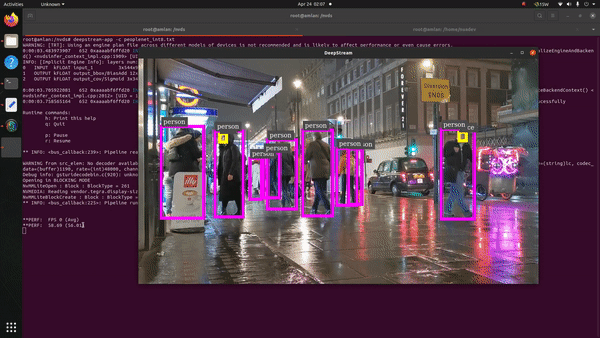
For 720p streaming output, we can notice from FP32 to FP16 the performance jump is around 52% (sweet!). Subsequently, the leap from FP16 to INT8 is much lower, i.e., 14%. Similarly, in the case of 1080p rendered output the performance increase from FP32 to FP16 is around 31% (still great!). However, the jump from FP16 to INT8 is very low at 5%. The lower FP16 to INT8 performance transition in both the cases could be because of incomplete model conversion across all layers to INT8 format (which we observed apparently during the process).
Traffic Analytics
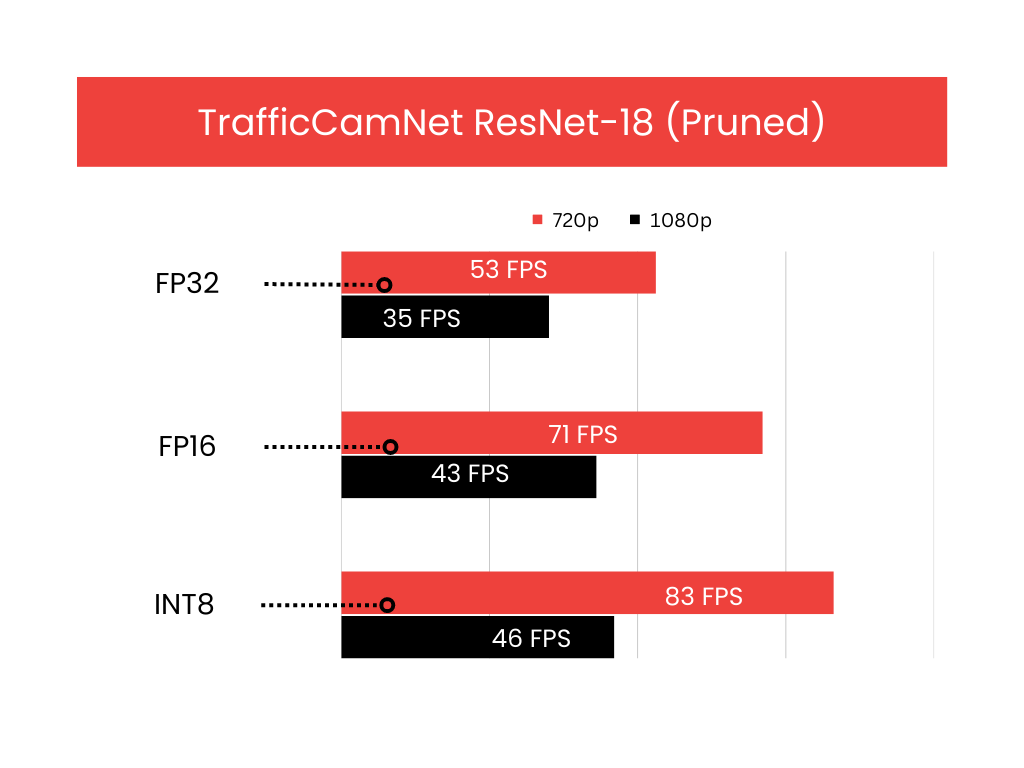
Our next focus was on analyzing traffic patterns on a busy urban street using the TrafficCamNet model, which is also available as a pre-trained model card in the NGC catalogue. This object-detection model is designed to identify cars, pedestrians, road-signs and two-wheelers on input frames or images, and can also handle frame sizes up to 960x544X3. We performed similar tests as that of PeopleNet across all precision modes.

One key difference here is that the backbone of the detection network is ResNet18 which has fewer parameters compared to ResNet-34. Hence, we noticed a significant performance difference between the two models.
Our observations show that for 720p output streaming, the performance gain interestingly from FP32 to FP16 was around 34%. Additionally, the improvement from FP16 to INT8 was comparatively smaller, at 17%. Similarly, for 1080p output, the performance improvement from FP32 to FP16 was 23%, which is still quite impressive. However, the increase from FP16 to INT8 was only 7%. Once again, we suspect that the limited performance boost from FP16 to INT8 could be due to incomplete model conversion across all layers to the INT8 format, which we observed during the process.
Action Recognition
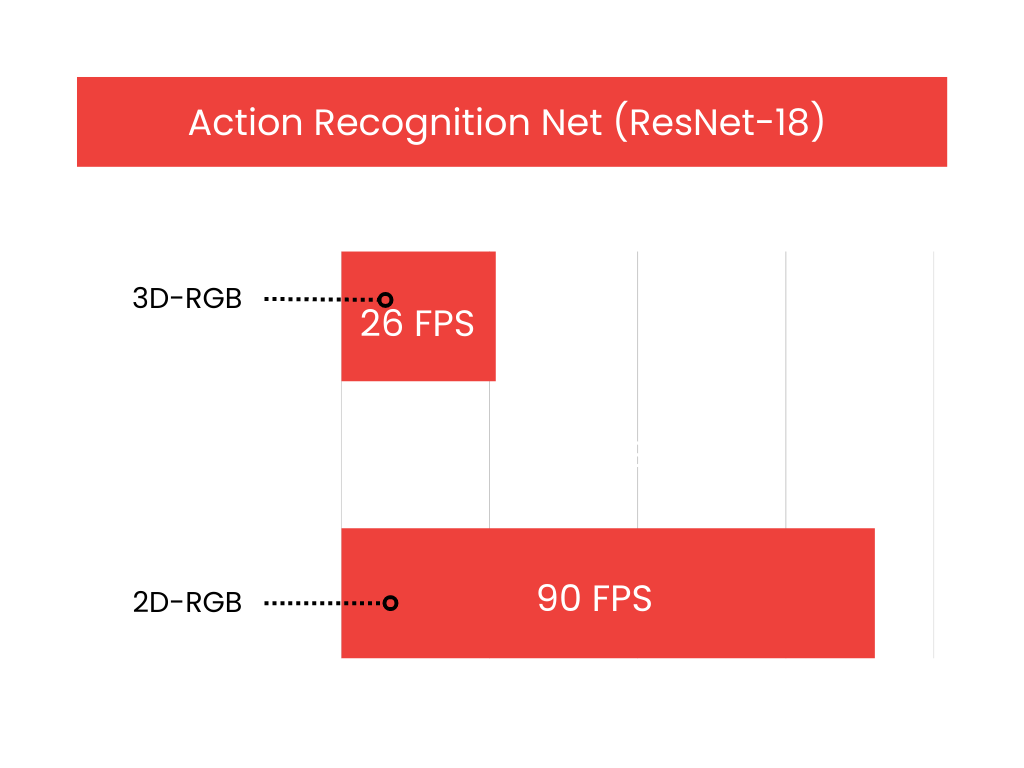
Next in our list was to evaluate how the Jetson Orin Nano behaves with the Action Recognition Net, which is one of the pre-trained models available at NGC. The model takes a series of images/frames constituting an action as input and classifies the respective action. It is available in two flavours: 2D-RGB & 3D-RGB, the backbone of both being ResNet-18. The 2D model takes the grayscale transform of the original footage as input for inference whereas the 3D version takes the RGB channels into account.
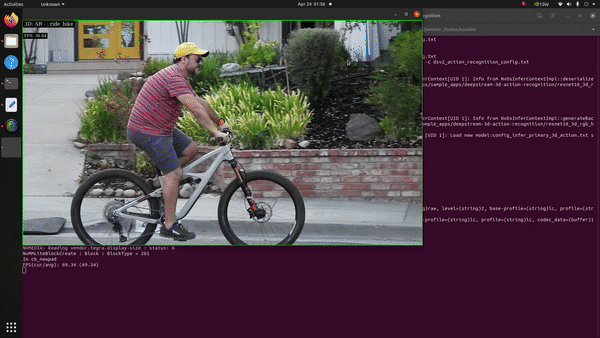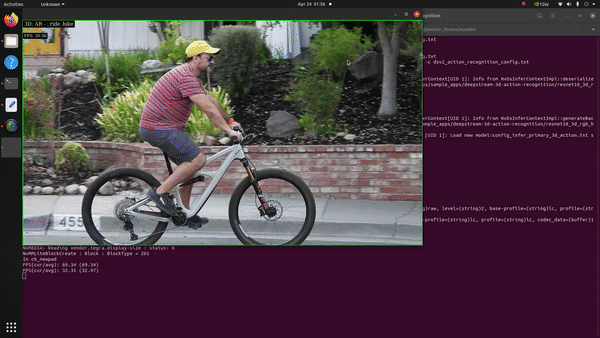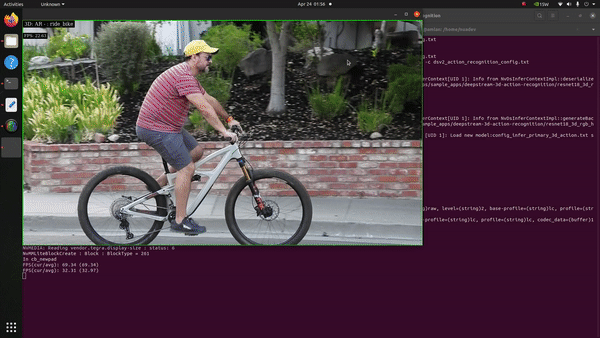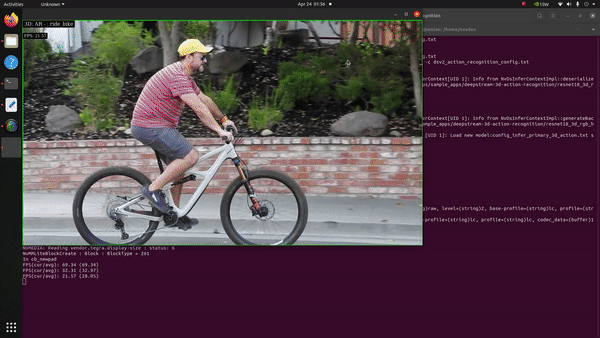
It’s evident that an action recognition model is a heavy-duty juggernaut given the sheer number of complexities involved in classifying a series of frames bunched together as the input in one-go. To our surprise, upon testing both the input models for inference in FP16 mode, we discovered that the Jetson Orin Nano did a fantastic job. With the 3D-RGB model we witnessed around 26 FPS performance on inference and output rendering.
The 2D-RGB variant on the other hand showcased a whooping 90 FPS output inference! How much of a difference in performance is it when we compare the same with other Jetson devices?
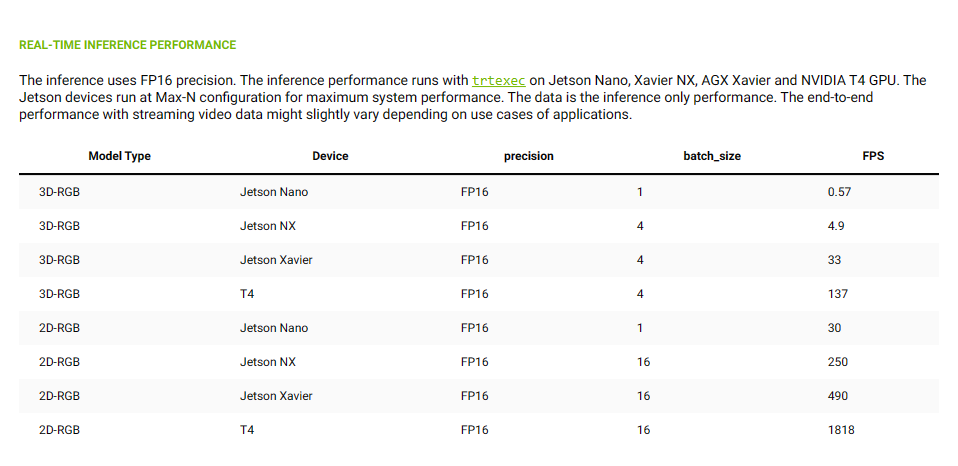
While it may not be a fair comparison of Jetson Orin Nano with its predecessor architecture counterparts, it’s very important to consider the leap in performance from older to newer generation. The image above depicts the Action-Recognition-Net inference-only benchmark (no output rendering) on both edge and some data-center based GPU inference infrastructure. It is evident to say that the Orin Nano has already outperformed Nano, Xavier NX and AGX Xavier by a good margin!
N-Body Simulation
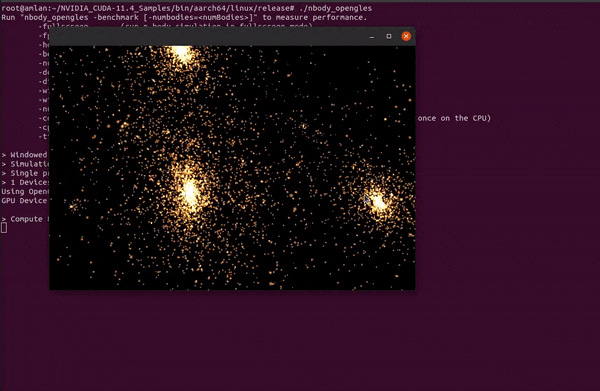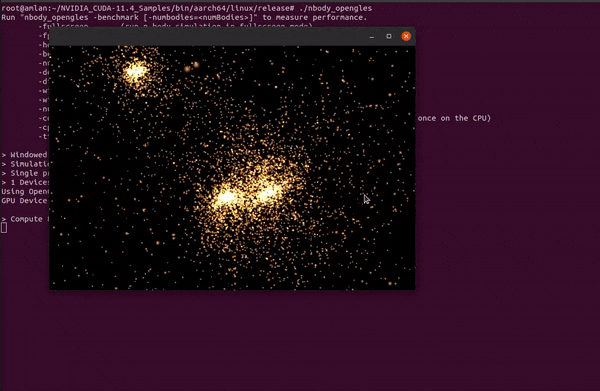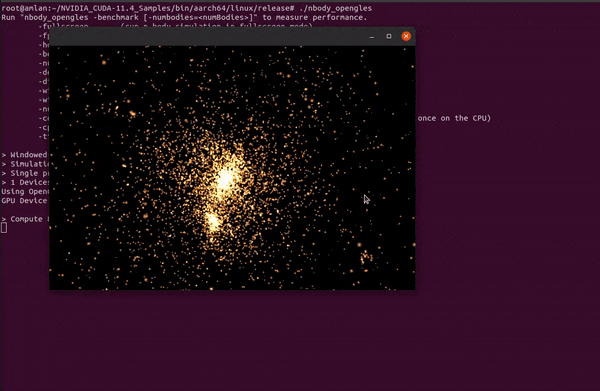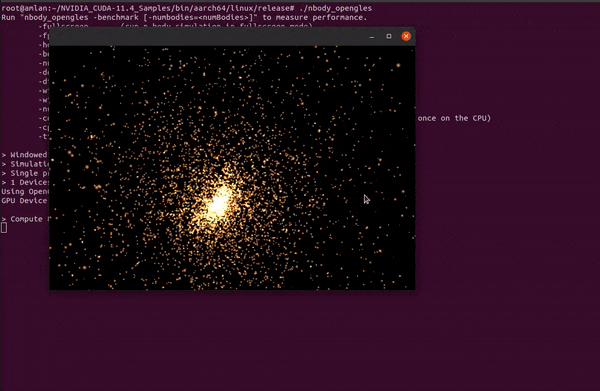
The next thing that came to our mind was to judge how the Jetson Orin Nano fared with graphics simulation applications. Accordingly, we picked the n-body simulation example which is available as a part of CUDA samples that can be executed on Jetson.
N-Body Simulation is a technique/tool that astrophysicists use to understand how groups of particles, like stars and planets, interact with each other in space. By researching how these particles move and collide, scientists can learn more about how galaxies form and behave on a larger scale. Hence, it must be quite evident that the computations involved in making the simulation possible will be herculean in nature!
Running the simulation led to a window pop-op that showcased movement of such particles leading to the creation of beautiful patterns. The benchmarks for a total of 10 iterations consumed a wall time of around 38.6 milliseconds. Most noteworthy, the Orin Nano was able to perform at around 347 GFLOPSs (Giga Floating Point Operations Per Second – FP32)!
FluidsGLES
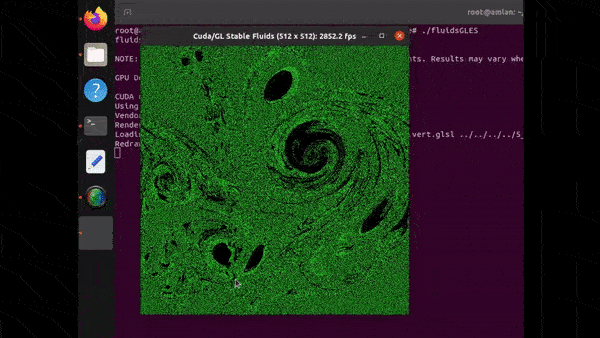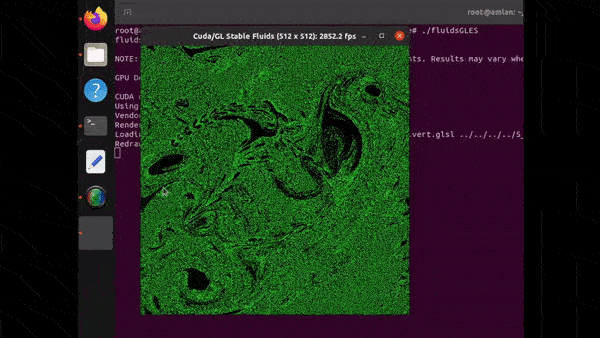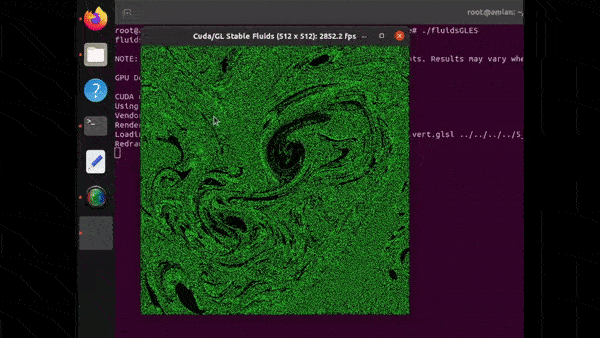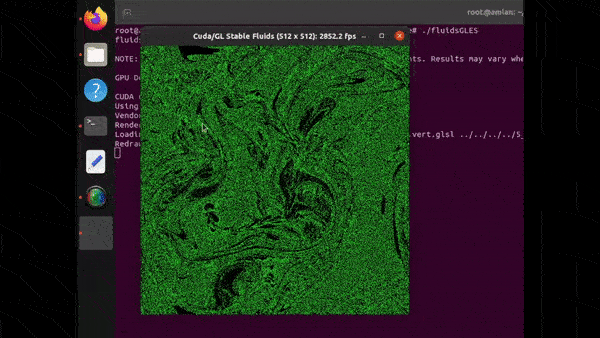
FluidsGLES is a fluid simulation that is achieved using CUDA, its HPC library for Fast-Fourier-Transforms (CuFFT) and OpenGLES. The simulation is interactive. Once it is launched, one can click on the simulation window and move the cursor around to influence the fluid dynamics. It’s certainly a cool demo to try out and uncover the uncharted possibilities of any GPU-accelerated device. The accuracy, fluidity and smoothness of the spiral patterns rendered will leave you mesmerized.
On Jetson Orin Nano, when executed, the simulation rendering rate was roughly 2900 FPS for a 512×512 resolution output.
Marvel vs Capcom

Enough with AI & HPC benchmarks! It was time for us to do what the Tegra chips were originally designed for – console/mobile gaming! Nothing stopped us from exploiting the Tegra Orin beast’s shading prowess and hence, we embarked on an adventure to check out if it could run any games or not. It was very challenging to find the right emulators which could detect the GPU on the Orin Nano. Almost all of them would run on CPU with unoptimized OpenGL backend.

Hence, the games would eventually run slow at a very poor framerate. Nonetheless, we were able to run one of the oldest games in the console industry – Marvel vs Capcom! We managed to play it with PCSX emulator alas! Not sure which backend it was utilizing but we were able to see GPU usage (30-50%) in Jetson Power GUI. However, it was not being utilized to its full potential. It will be very interesting to hunt for an optimized emulator supporting Vulkan API that would definitely push the Orin Nano to its limits.
Nonetheless, it was super fun playing as Ryu vs Zangief with a controller connected wirelessly to Jetson Orin Nano.
Verdict
As per our initial overview and evaluation, the NVIDIA Jetson Orin Nano dev kit is definitely a fantastic beast that can be added to your AI arsenal provided you have the requirement for it. With a greater number of complex multimodal models coming out every day, I would say NVIDIA has built a highly performant Edge AI System-on-Module (SoM) to adapt to recent advancements in the industry. Even with the lack of a hardware-encoder, it was still surprising to witness how the tiny juggernaut could render inference output streams at a very high frame rate.

There is certainly more to explore on its capabilities but with the experience witnessed so far, the Jetson Orin Nano developer kit is indeed a beautiful and powerful device to experiment with. It will be intriguing to see how the community tries to adapt and grow with it. However, when it comes to being called as the older Jetson Nano’s successor, there are a few caveats. The predecessor plainly can’t be compared in terms of specifications and performance, but it was priced at $120. It already established significant popularity in the community as, “The cheapest GPU-accelerated AI computer that money can buy”.
Hence, the old Jetson Nano became a symbol with its lower price and also as the next higher upgrade after a Raspberry Pi4. Priced at $499, the Jetson Orin Nano 8GB Developer Kit on the other hand definitely packs a powerful ammunition but has a few minute things missing. A DLA, hardware-encoder and an additional HDMI port could have been squeezed into the SoM. HDMI, however, is supported on the Orin Nano production module, it’s just not brought out on the Orin Nano developer kit.
There will definitely be a big pool of audience hungry to get hands on this dev kit, but we do think the larger community will also be interested in a 4GB variant. The good thing is that NVIDIA has a full line of dev kits and production modules available (see below), and the new dev kit technically supports swapping out the modules!


In the future, we are interested in exploring the feature of replacing the Orin modules. This is a good way for businesses to rapidly prototype and later choose production module of their choice as requirements scale.
We would be coming back with interesting tutorials based on the Jetson platform and more benchmarks in the future. Till then stay tuned and let us know your thoughts about Jetson Orin Nano in the comments below!
3 Comments
joe valdivia
The article was very nicely done.
Amlan Panigrahi
Thank you Joe!